
Goodbye text prompts? Thinking Machines just unveiled the real-time AI collaborator meant to replace them.
Welcome to Road to AI, your favourite newsletter that tracks everything happening in AI so you don’t have to.
Here is what we have for you today:
The main course:
Is Thinking Machines' model the right solution for human-AI interactive collaboration?
The dessert (from our channels to yours):
Anthropic courts a new kind of customer: small business owners
Google introduced a new category of laptops that goes all in on AI
WhatsApp launches totally private ‘incognito’ conversations with its AI chatbot
Amazon launches an AI shopping assistant for the search bar, powered by Alexa+
Google just reimagined a 50-year-old interface - the mouse pointer - with AI

If you’ve seen the Iron Man movies, you probably remember most of the scenes where Tony Stark is working on his armour and other experiments while talking out loud to his AI assistant JARVIS.
Watching an advanced AI assistant seamlessly read the physical environment, adjust calculations on the fly, and anticipate problems probably made a lot of people think: “Man, I wish I had one.”

We obviously have AI assistants today, but interacting with them is basically like a walkie-talkie dynamic.
We talk to them, they respond back, and do it again in one continuous loop.
If what Thinking Lab Machines announced this week works, that loop is about to break.
After a long silence working in the background since leaving OpenAI, Mira Murati unveiled the new model with a completely new approach.
In short, it could give us the kind of AI interaction Tony Stark had with JARVIS (just not with everything JARVIS could do).
Her bet is actually that future AI models need to be built around continuous, real-time interaction from the ground up, rather than bolting voice and vision features onto an intelligence layer that is already finished.
If Thinking Machines can actually pull this off, AI could shift from a “prompt in, answer out” tool to something that feels a lot more like real collaborative work.
Bigger than it sounds at first glance
Thinking Machines hasn’t just unveiled “ChatGPT, but better.”
Instead, they’ve introduced something that addresses a much deeper issue: the very way we interact with AI.
It is a new concept called: “interaction models.”
The idea behind interaction models, according to Thinking Machines, is that they will let people collaborate with AI the way we naturally collaborate and talk with each other.
Here is the problem they are solving.
Current AI models experience reality in a single thread.
The model waits for you to finish speaking, processes everything you said, and then responds.
While it is generating that response, its view of what is happening around you is completely frozen.
Thinking Machines describe this as forcing humans to “contort themselves” to fit the AI, or simply batching thoughts into neat prompts, waiting for a full answer before reacting.
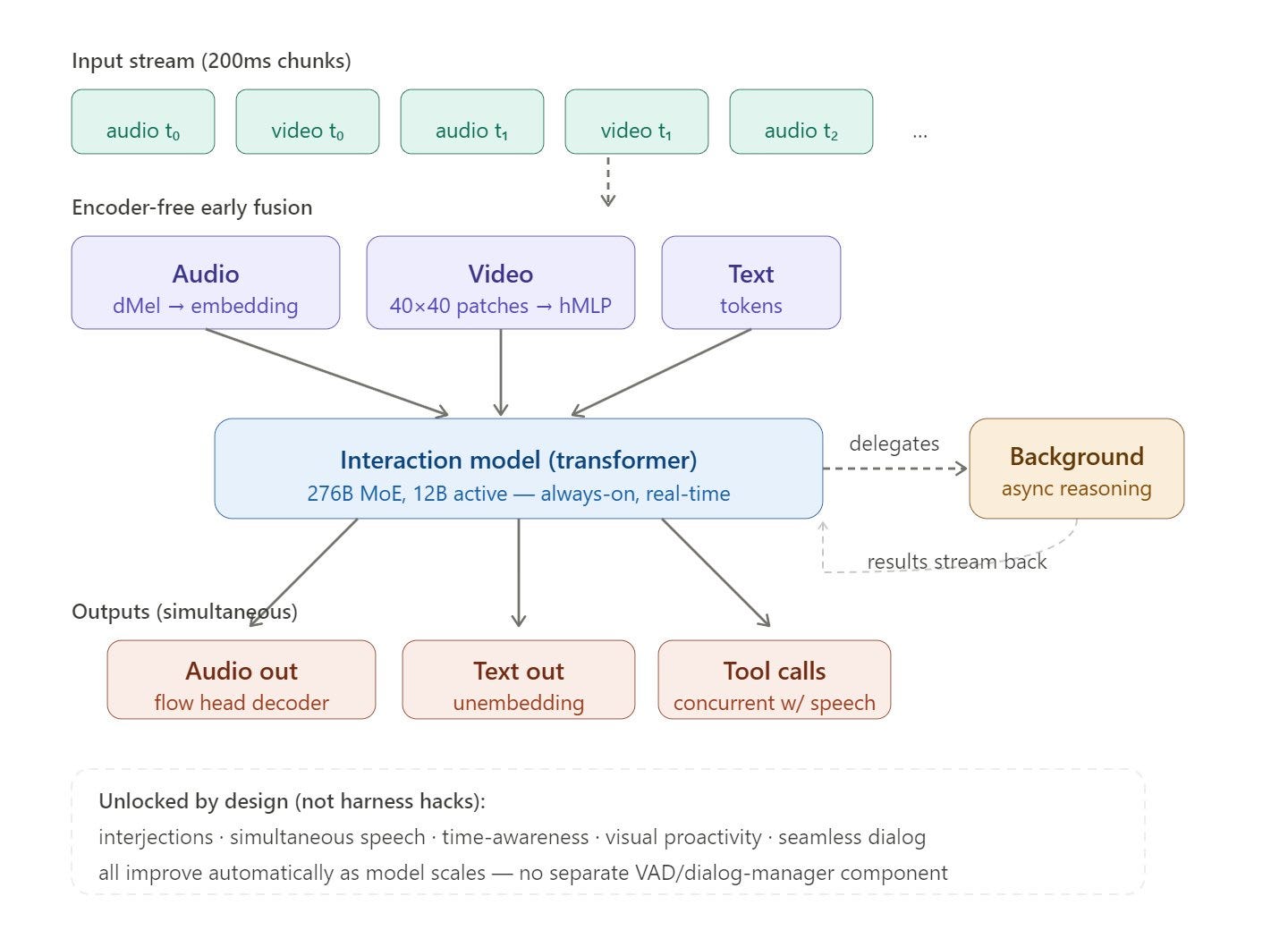
Their fix is called a multi-stream, micro-turn design.
In plain terms, instead of waiting for you to finish and then thinking, the model processes 200-millisecond chunks of audio, video, and text simultaneously and continuously.
Think of the difference between a phone call and a text conversation.
A text conversation is what you have with every AI assistant today.
Thinking Machines built something that is closer to a phone or video call, where both sides are present at the same time and the conversation moves in real time.
The two-part system behind it
There is one technical detail worth understanding because it explains how the model handles both speed and intelligence at the same time.
Real-time interaction and deep reasoning pull in opposite directions.
Responding in 0.40 seconds does not leave much room for thinking through a complex problem.
Thinking Machines solved this by splitting the work between two models running in parallel.
The interaction model stays in constant contact with you. It handles the conversation, the presence, and the immediate back-and-forth.
The background model handles the heavy lifting: sustained reasoning, web browsing, and complex tool calls. It streams its results back to the interaction model, which weaves them into the conversation naturally.
In practice, this means the AI can generate a chart, run a web search, or work through a multi-step problem in the background while still being fully present in the conversation with you.
You do not wait for it to finish thinking before it acknowledges what you just said.
How It performs against other models
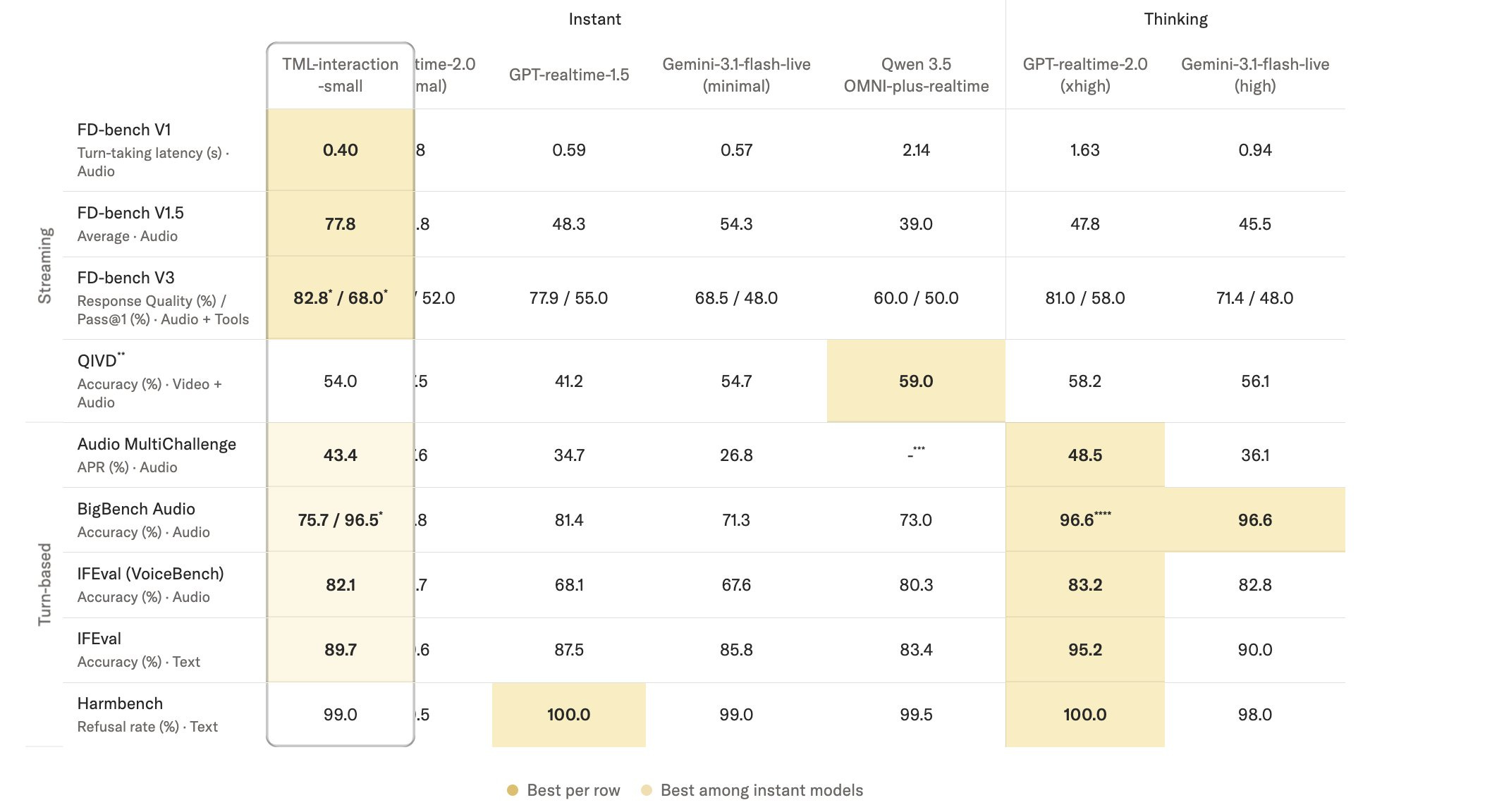
To measure this, Thinking Machines used something called FD-bench.
It is basically a benchmark designed specifically to test interaction quality rather than raw intelligence.
Most AI benchmarks measure how smart a model is.
FD-bench measures how well it actually functions in a real conversation — handling interruptions, responding at the right moment, managing background noise, reacting when someone else enters the room.
On FD-bench V1.5, TML-Interaction-Small scored 77.8. OpenAI’s GPT-Realtime-2 scored 46.8 on the same test. Gemini-3.1-flash-live scored 54.3.
On response latency, the model clocks in at 0.40 seconds.
For context, a natural human conversation runs at roughly that same speed. GPT-Realtime-2 comes in at 1.18 seconds, which is the processing gap you notice as that slight but consistent pause before the AI starts talking.
On visual tasks, the gap gets wider.
When the model was asked to count physical repetitions in a video or answer questions based on what it was actively watching, every competing model either stayed silent or got it wrong. Thinking Machines' model got it right.
While these numbers sound good, there is one important caveat: these are company-reported figures.
Independent verification has not happened yet, and that matters before drawing firm conclusions.
But, besides those numbers, they also released early demos.
In one, the model handles live speech translation in real time, not sentence by sentence after a pause, but continuously as the person is speaking.
In another, it watches a video feed and calls out the user for slouching at their desk mid-session, without being asked to monitor anything.
The model noticed the visual cue and said something on its own.
What are the implications if this works out?
The enterprise implications of this are worth spelling out because they go beyond making chatbots feel more natural.
In a manufacturing or lab setting, a model that watches a video feed continuously can flag a safety violation or a deviation from protocol the moment it happens, not after a worker stops to ask whether something looks wrong.
In customer service, the 0.40-second latency means a support conversation feels like talking to a person rather than waiting for a system to catch up.
The model could also acknowledge what a customer is saying with natural cues while it is still processing the full request, the same way a human agent would say “I see” or “got it” while looking something up.
There is also a time-awareness capability that sounds simple but is not. Standard AI models have no internal clock.
They only know about time if you tell them. Thinking Machines’ model is natively time-aware, meaning you can say “alert me if this process takes longer than the last one” and it will track that on its own.
For industrial maintenance or pharmaceutical research where timing is a critical variable, that is a meaningful difference from anything currently available.

Anthropic courts a new kind of customer: small business owners
Google introduced a new category of laptops that goes all in on AI
WhatsApp launches totally private ‘incognito’ conversations with its AI chatbot
Amazon launches an AI shopping assistant for the search bar, powered by Alexa+
Google just reimagined a 50-year-old interface - the mouse pointer - with AI
Tweet of the day
The publication “thehype” just launched a continuous, entirely AI-powered online radio station featuring five distinct AI hosts that analyze breaking industry news, funding rounds, and repository trends for AI founders and developers.
The station streams 24/7 across X, YouTube, and radio.thehype.news with zero scheduled downtime and no human presenters at the controls.
The format relies on five AI hosts engineered with persistent memory and distinct editorial positions; instead of just reading headlines, they synthesize data, form arguments, and debate each other live on air.

One more thing…
That’s all from us today - catch you next week. But before you leave, tell us what did you think of today’s edition to help us improve the experience for you.
P.S. Did someone forward this to you? You can subscribe here